# SkyWalking吞吐量调优
# 背景介绍
SkyWalking主要组件由以下4个组成:
- Probes collect data and reformat them for SkyWalking requirements (different probes support different sources).
- Platform backend supports data aggregation, analysis and streaming process covers traces, metrics, and logs.
- Storage houses SkyWalking data through an open/plugable interface. You can choose an existing implementation, such as ElasticSearch, H2, MySQL, TiDB, InfluxDB, or implement your own. Patches for new storage implementors welcome!
- UI is a highly customizable web based interface allowing SkyWalking end users to visualize and manage SkyWalking data.
我们使用了Elasticsearch作为Storage,主要任务是调优SkyWalking从Probe -> Platform backend -> Storage的TraceSegments数据采集上报流程
# 搭建基准测试流程
在我们开始调优之前,需要将调优的目标制定下来,初步以单机Platform backend承受C10K(即每秒Concurrent 10k)作为第一阶段目标,当然了,由于SkyWalking是一个监控了整个业务系统的存在,我们的业务系统下主要是基于Java的SpringBoot微服务,可能一个实例的单一接口的并发请求量就会达到C10K这个量级,而多个接口多个实例在这里是非常轻松能让并发量变成一个非常恐怖的数值的,不过我们这里主要是为了让统计数值尽可能不丢失
我们会以分钟为维度来统计并发量级,而非秒,这里主要是出于对统计准确性来考虑的,因为SkyWalking无论是Probe还是Platform backend都采用的是使用Buffer的方式批量上报以及落库,以秒为维度会让数据波动过大,显示不那么直观。那么,以分钟为维度,我们的目标按C10K来算就是每分钟并发请求数必须达到600k
至此,我们至少需要一个测试应用,它能以QPS为10k的方式执行方法,并且被SkyWalking的Probe采集到,这里我们直接写了一个简单的类来实现,每秒钟会产生一个定时任务,定时任务会去执行10k次标准输出,代码如下:
package com.example.demo;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class C10K {
public static void main(String[] args) {
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
threadPool.scheduleAtFixedRate(new Scheduler(), 0, 1, TimeUnit.SECONDS);
}
public static class Scheduler implements Runnable {
@Override
public void run() {
ExecutorService threadPool = Executors.newFixedThreadPool(100);
for (int i = 0; i < 10000; i++) {
threadPool.execute(new Worker());
}
threadPool.shutdown();
}
}
public static class Worker implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": Worker is running");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
我们也还至少需要一个能查询到Storage中数据的统计脚本(我们这里只关注segment索引,它是SkyWalking用来存储TraceSegment元数据的地方)
import time
import requests
import json
last_count = 0
def count():
response = requests.get('http://w.x.y.z:8080/elasticsearch/skywalking_segment-20210516/type/_count')
body = json.loads(response.text)
return body['count']
def main():
while True:
global last_count
current = count()
diff = current - last_count
last_count = current
print('[%s] current: %s, diff: %s' % (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), current, diff))
time.sleep(60)
if __name__ == '__main__':
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
准备就绪,这里关于搭建SkyWalking的细节不就展开赘述了,使用下面命令启动起来看看吧(这里其实还省略了一些细节,我们这里选择了SkyWalking的customize-enhance-plugin来完成对Worker#run方法的Span生成)
# 启动测试应用c10k-demo.jar
java -javaagent:/opt/app/scout/scout-agent-aot/skywalking-agent.jar -DSW_AGENT_NAME=scout-agent-demo -jar c10k-demo.jar 2>&1 > console.log &
# 查看测试应用日志
tail -f /opt/app/scout/console.log
2
3
4
测试应用日志输出如下:
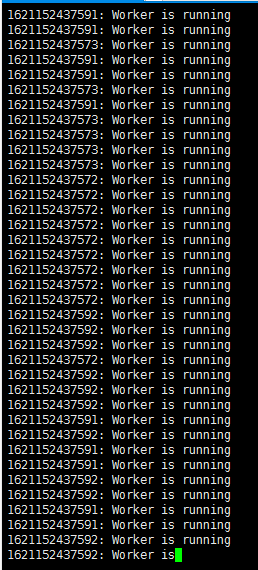
实测下来发现200ms以内就可以完成10k次请求的模拟,能够满足我们的压测需求
再来使用
# 查看SkyWalking的Probe日志
tail -f /opt/app/scout/scout-agent-aot/logs/skywalking-api.log
2
来观察SkyWalking的Probe端日志:
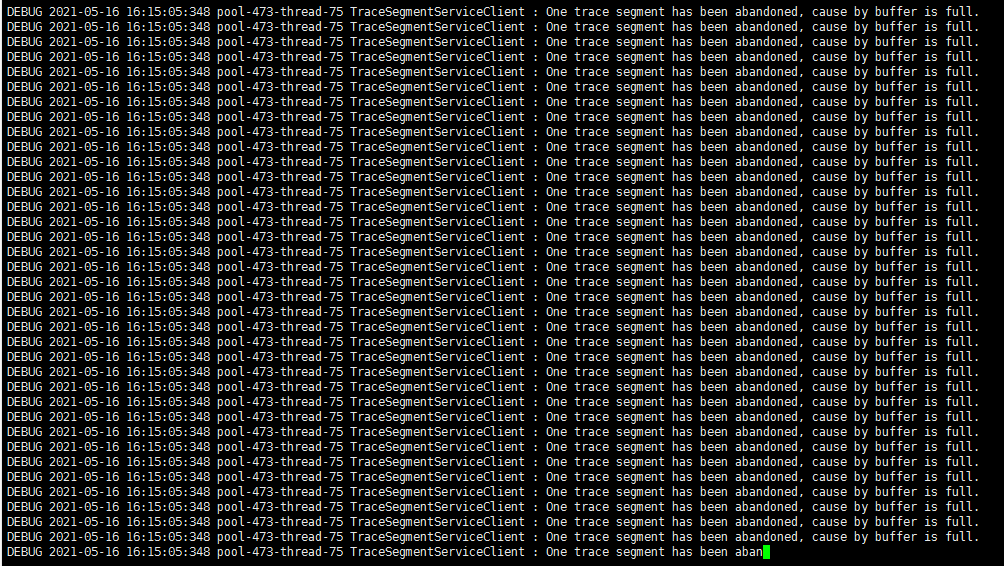
发现缓冲区已经溢出,开始丢弃trace segment了
再观察Platform backend端日志:
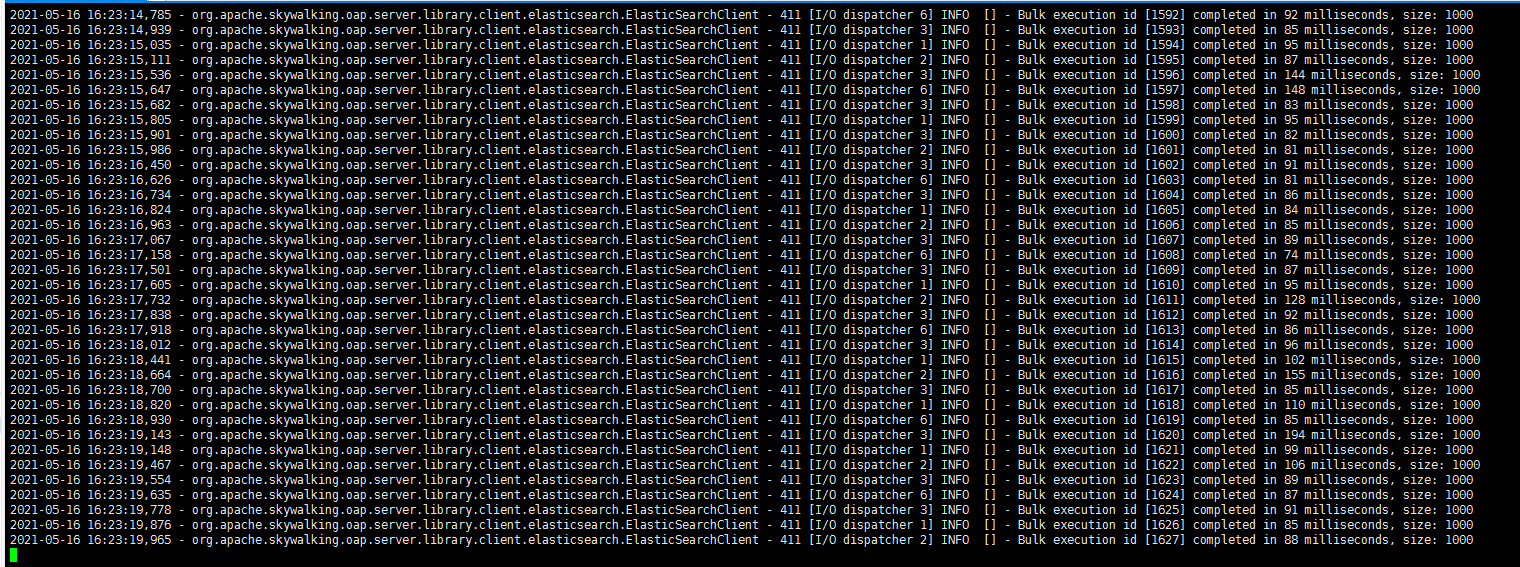
并没有发现什么超时异常或者丢弃数据之类的日志,看起来挺正常的
这里有一点需要注意,因为Java8起,SkyWalking会用gRPC协议来替代之前的HTTP协议传输数据,所以这里哪怕我们的backend端是部署的双机,仍然只会有一台实例能够接收到采集的trace segment数据
再看下之前我们用Python脚本实现的统计Storage中的数据量:
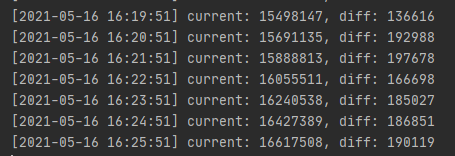
基本上是稳定在了2w以下,那么我们可以粗略总结一下现状了
从日志来看目前是probe端部分数据因为缓冲池不够大而开始被丢弃
# 优化思路一:将Probe端缓冲池扩容
我们根据日志信息来顺藤摸瓜,”One trace segment has been abandoned“是个非常明显的特征
package org.apache.skywalking.apm.agent.core.remote;
// ...
/**
* @author wusheng
*/
@DefaultImplementor
public class TraceSegmentServiceClient implements BootService, IConsumer<TraceSegment>, TracingContextListener, GRPCChannelListener {
// ...
@Override
public void afterFinished(TraceSegment traceSegment) {
if (traceSegment.isIgnore()) {
return;
}
if (!carrier.produce(traceSegment)) {
if (logger.isDebugEnable()) {
logger.debug("One trace segment has been abandoned, cause by buffer is full.");
}
}
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在TraceSegmentServiceClient中发现,如果if (!carrier.produce(traceSegment))就会导致这个错误日志,我们继续来看carrier的produce方法做了什么
package org.apache.skywalking.apm.commons.datacarrier;
// ...
/**
* DataCarrier main class. use this instance to set Producer/Consumer Model.
*/
public class DataCarrier<T> {
// ...
/**
* produce data to buffer, using the given {@link BufferStrategy}.
*
* @param data
* @return false means produce data failure. The data will not be consumed.
*/
public boolean produce(T data) {
if (driver != null) {
if (!driver.isRunning(channels)) {
return false;
}
}
return this.channels.save(data);
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package org.apache.skywalking.apm.commons.datacarrier.buffer;
// ...
/**
* Channels of Buffer It contains all buffer data which belongs to this channel. It supports several strategy when
* buffer is full. The Default is BLOCKING <p> Created by wusheng on 2016/10/25.
*/
public class Channels<T> {
// ...
public Channels(int channelSize, int bufferSize, IDataPartitioner<T> partitioner, BufferStrategy strategy) {
this.dataPartitioner = partitioner;
this.strategy = strategy;
bufferChannels = new QueueBuffer[channelSize];
for (int i = 0; i < channelSize; i++) {
if (BufferStrategy.BLOCKING.equals(strategy)) {
bufferChannels[i] = new ArrayBlockingQueueBuffer<T>(bufferSize, strategy);
} else {
bufferChannels[i] = new Buffer<T>(bufferSize, strategy);
}
}
size = channelSize * bufferSize;
}
// ...
public boolean save(T data) {
int index = dataPartitioner.partition(bufferChannels.length, data);
int retryCountDown = 1;
if (BufferStrategy.IF_POSSIBLE.equals(strategy)) {
int maxRetryCount = dataPartitioner.maxRetryCount();
if (maxRetryCount > 1) {
retryCountDown = maxRetryCount;
}
}
for (; retryCountDown > 0; retryCountDown--) {
if (bufferChannels[index].save(data)) {
return true;
}
}
return false;
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
package org.apache.skywalking.apm.commons.datacarrier.partition;
/**
* use threadid % total to partition
*
* Created by wusheng on 2016/10/25.
*/
public class ProducerThreadPartitioner<T> implements IDataPartitioner<T> {
// ...
@Override
public int partition(int total, T data) {
return (int)Thread.currentThread().getId() % total;
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package org.apache.skywalking.apm.agent.core.remote;
// ...
/**
* @author wusheng
*/
@DefaultImplementor
public class TraceSegmentServiceClient implements BootService, IConsumer<TraceSegment>, TracingContextListener, GRPCChannelListener {
// ...
@Override
public void boot() throws Throwable {
lastLogTime = System.currentTimeMillis();
segmentUplinkedCounter = 0;
segmentAbandonedCounter = 0;
carrier = new DataCarrier<TraceSegment>(CHANNEL_SIZE, BUFFER_SIZE);
carrier.setBufferStrategy(BufferStrategy.IF_POSSIBLE);
carrier.consume(this, 1);
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
至此基本上就清楚核心逻辑了,SkyWalking设计了一个非常精巧的叫DataCarrier的结构,DataCarrier里边有Channels<T> channels,channels里边存放了QueueBuffer<T>[] bufferChannels,IDataPartitioner<T> dataPartitioner和BufferStrategy strategy,当调用了DataCarrier#produce时,会将数据先根据当前线程ID与来分配一个根据bufferChannels.length即channels的数量来取余计算出的一个分区号,将数据均匀写入多个channel的buffer中,这里strategy有BLOCKING和IF_POSSIBLE可选,BLOCKING会让bufferChannels采用ArrayBlockingQueueBuffer<T>[]的数据结构,而IF_POSSIBLE则会采用Object[],可以从TraceSegmentServiceClient#boot看到,在处理TraceSegment写入缓冲区的时候,使用的是IF_POSSIBLE策略,其中就发现了CHANNEL_SIZE, BUFFER_SIZE的指定,正是我们要找的地方
package org.apache.skywalking.apm.agent.core.conf;
// ...
/**
* This is the core config in sniffer agent.
*
* @author wusheng
*/
public class Config {
// ...
public static class Buffer {
public static int CHANNEL_SIZE = 5;
public static int BUFFER_SIZE = 300;
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
可知读取的是Config类中的这两处属性,那么问题迎刃而解了,之前我们解读过SkyWalking的Probe加载机制的源码,不知大家是否还有印象,我们只需要在配置文件加上这两行,并重启测试应用就可以生效了
buffer.channel_size=${SW_BUFFER_CHANNEL_SIZE:10}
buffer.buffer_size=${SW_BUFFER_BUFFER_SIZE:1000}
2
这里我们设置大一些,虽然可能或多或少影响到宿主应用的资源占用情况,但也不妨一试
再看Probe日志:
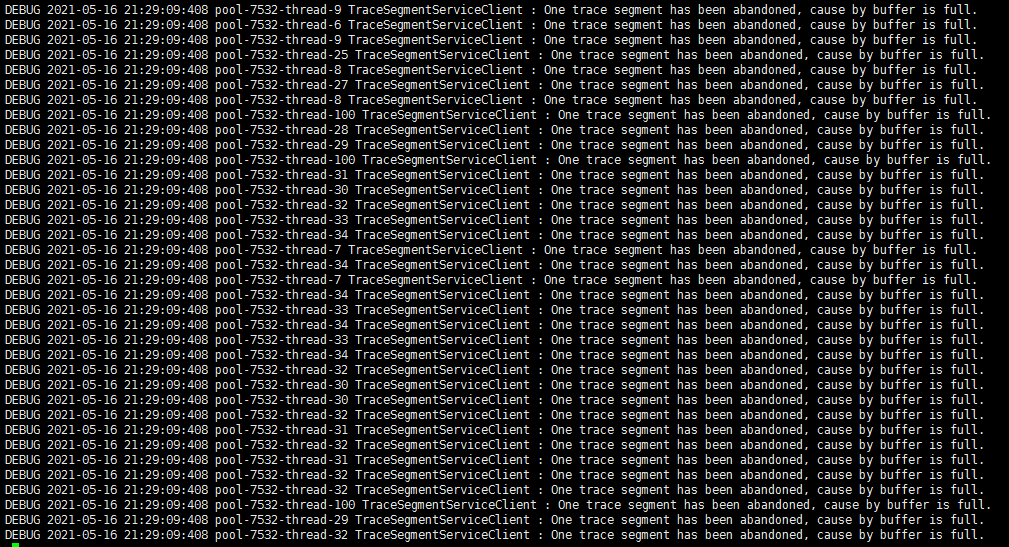
Python统计脚本日志:
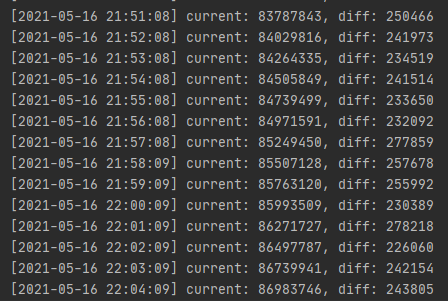
意料之中,虽然发现吞吐量从2w以下提升到了2w5左右,有了25%左右提升,但是缓冲区依旧能被堆满,这种方式依然是有些治标不治本的
# 优化思路二:将Backend端写库线程池扩容
package org.apache.skywalking.apm.agent.core.remote;
// ...
@DefaultImplementor
public class TraceSegmentServiceClient implements BootService, IConsumer<TraceSegment>, TracingContextListener, GRPCChannelListener {
// ...
@Override
public void boot() {
lastLogTime = System.currentTimeMillis();
segmentUplinkedCounter = 0;
segmentAbandonedCounter = 0;
carrier = new DataCarrier<>(CHANNEL_SIZE, BUFFER_SIZE); // 初始化carrier实例
carrier.setBufferStrategy(BufferStrategy.IF_POSSIBLE); // 设置carrier的写入策略
carrier.consume(this, 1); // 初始化carrier里的consumer线程
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在probe被初始化的时候,所有的BootService都会被加载,其中当它的实例之一TraceSegmentServiceClient的boot()方法被执行的时候,carrier.consume(this, 1);会初始化carrier内部的所有consumerThreads来开始消费buffer
package org.apache.skywalking.apm.commons.datacarrier;
// ...
/**
* DataCarrier main class. use this instance to set Producer/Consumer Model.
*/
public class DataCarrier<T> {
// ...
/**
* set consumeDriver to this Carrier. consumer begin to run when {@link DataCarrier#produce} begin to work with 20
* millis consume cycle.
*
* @param consumer single instance of consumer, all consumer threads will all use this instance.
* @param num number of consumer threads
*/
public DataCarrier consume(IConsumer<T> consumer, int num) {
return this.consume(consumer, num, 20); // 跳转如下方法
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
package org.apache.skywalking.apm.commons.datacarrier;
// ...
/**
* DataCarrier main class. use this instance to set Producer/Consumer Model.
*/
public class DataCarrier<T> {
// ...
/**
* set consumeDriver to this Carrier. consumer begin to run when {@link DataCarrier#produce} begin to work.
*
* @param consumer single instance of consumer, all consumer threads will all use this instance.
* @param num number of consumer threads
*/
public DataCarrier consume(IConsumer<T> consumer, int num, long consumeCycle) {
if (driver != null) {
driver.close(channels);
}
driver = new ConsumeDriver<T>(this.name, this.channels, consumer, num, consumeCycle); // 根据num作为线程数量,consumeCycle作为空闲时线程sleep时长创建driver
driver.begin(channels); // 这里传入的channels实际上没有用到,启动所有consumer线程
return this;
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package org.apache.skywalking.apm.commons.datacarrier.consumer;
// ...
/**
* Pool of consumers <p> Created by wusheng on 2016/10/25.
*/
public class ConsumeDriver<T> implements IDriver {
// ...
public ConsumeDriver(String name, Channels<T> channels, IConsumer<T> prototype, int num, long consumeCycle) {
this(channels, num);
prototype.init();
for (int i = 0; i < num; i++) { // 分配好所有ConsumerThread实例
consumerThreads[i] = new ConsumerThread("DataCarrier." + name + ".Consumser." + i + ".Thread", prototype, consumeCycle);
consumerThreads[i].setDaemon(true);
}
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package org.apache.skywalking.apm.commons.datacarrier.consumer;
// ...
/**
* Pool of consumers <p> Created by wusheng on 2016/10/25.
*/
public class ConsumeDriver<T> implements IDriver {
// ...
@Override
public void begin(Channels channels) {
if (running) {
return;
}
try {
lock.lock();
this.allocateBuffer2Thread();
for (ConsumerThread consumerThread : consumerThreads) {
consumerThread.start(); // 启动所有consumerThread
}
running = true;
} finally {
lock.unlock();
}
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
至此,consumerThreads就已经就绪,并且已经被全部启动,开始在源源不断地消费buffer,我们继续看下去,consumerThread的run()方法做了什么
package org.apache.skywalking.apm.commons.datacarrier.consumer;
// ...
public class ConsumerThread<T> extends Thread {
// ...
@Override
public void run() {
running = true;
final List<T> consumeList = new ArrayList<T>(1500);
while (running) {
if (!consume(consumeList)) { // 当buffer内有内容可消费时,就会返回true,否则false
try {
Thread.sleep(consumeCycle);
} catch (InterruptedException e) {
}
}
}
// consumer thread is going to stop
// consume the last time
consume(consumeList); // 这里在consumer thread停止前将剩余内容消费完
consumer.onExit();
}
private boolean consume(List<T> consumeList) {
for (DataSource dataSource : dataSources) {
dataSource.obtain(consumeList); // 调用buffer的obtain方法,将内容全部读入consumeList
}
if (!consumeList.isEmpty()) {
try {
consumer.consume(consumeList); // 这里开始真正处理从buffer中读取的内容
} catch (Throwable t) {
consumer.onError(consumeList, t);
} finally {
consumeList.clear();
}
return true;
}
return false;
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
这块逻辑就比较好理解,基本就是一个while (true)循环不断在读取buffer并写入consumeList,如果读不到就以consumeCycle来自旋等待,如果读到了就开始处理
package org.apache.skywalking.apm.agent.core.remote;
// ...
@DefaultImplementor
public class TraceSegmentServiceClient implements BootService, IConsumer<TraceSegment>, TracingContextListener, GRPCChannelListener {
// ...
@Override
public void consume(List<TraceSegment> data) {
if (CONNECTED.equals(status)) {
final GRPCStreamServiceStatus status = new GRPCStreamServiceStatus(false);
StreamObserver<UpstreamSegment> upstreamSegmentStreamObserver = serviceStub.withDeadlineAfter(
Config.Collector.GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS
).collect(new StreamObserver<Commands>() {
@Override
public void onNext(Commands commands) {
ServiceManager.INSTANCE.findService(CommandService.class)
.receiveCommand(commands);
}
@Override
public void onError(
Throwable throwable) {
status.finished();
if (logger.isErrorEnable()) {
logger.error(
throwable,
"Send UpstreamSegment to collector fail with a grpc internal exception."
);
}
ServiceManager.INSTANCE
.findService(GRPCChannelManager.class)
.reportError(throwable);
}
@Override
public void onCompleted() {
status.finished();
}
});
try {
for (TraceSegment segment : data) { // 这里开始把segment转成UpstreamSegment,用gRPC将数据发往backend了
UpstreamSegment upstreamSegment = segment.transform();
upstreamSegmentStreamObserver.onNext(upstreamSegment);
}
} catch (Throwable t) {
logger.error(t, "Transform and send UpstreamSegment to collector fail.");
}
upstreamSegmentStreamObserver.onCompleted();
status.wait4Finish();
segmentUplinkedCounter += data.size();
} else {
segmentAbandonedCounter += data.size();
}
printUplinkStatus();
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
package org.apache.skywalking.oap.server.receiver.trace.provider.handler.v6.grpc;
// ...
public class TraceSegmentReportServiceHandler extends TraceSegmentReportServiceGrpc.TraceSegmentReportServiceImplBase implements GRPCHandler {
// ...
@Override
public StreamObserver<UpstreamSegment> collect(StreamObserver<Commands> responseObserver) {
return new StreamObserver<UpstreamSegment>() {
@Override
public void onNext(UpstreamSegment segment) {
if (logger.isDebugEnabled()) {
logger.debug("receive segment");
}
HistogramMetrics.Timer timer = histogram.createTimer();
try {
segmentProducer.send(segment, SegmentSource.Agent); // 标记数据来源为Agent(另一个是Buffer,这个稍后会讲),并把数据继续传递
} finally {
timer.finish();
}
}
@Override
public void onError(Throwable throwable) {
logger.error(throwable.getMessage(), throwable);
responseObserver.onCompleted();
}
@Override
public void onCompleted() {
responseObserver.onNext(Commands.newBuilder().build());
responseObserver.onCompleted();
}
};
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
通过onNext方法的连接,不经意已经将数据从probe传到了backend,这就是rpc的魅力吧,调用过程与本地方法无异,这里值得一说的是,走gRPC为什么不将多个segment批量传输呢,非要一个个的,前面做了buffer岂不是无用功,其实仔细想想不是这样的,因为segment已经是一个集合了,它里边还包含了多个span,所以没必要再进行一次批量传输也是可以理解的
package org.apache.skywalking.oap.server.receiver.trace.provider.parser;
// ...
/**
* SegmentParseV2 replaced the SegmentParse(V1 is before 6.0.0) to drive the segment analysis. It includes the following
* steps
*
* 1. Register data, name to ID register
*
* 2. If register unfinished, cache in the local buffer file. And back to (1).
*
* 3. If register finished, traverse the span and analysis by the given {@link SpanListener}s.
*
* 4. Notify the build event to all {@link SpanListener}s in order to forward all built sources into dispatchers.
*
* @since 6.0.0 In the 6.x, the V1 and V2 analysis both exist.
* @since 7.0.0 SegmentParse(V1) has been removed permanently.
*/
@Slf4j
public class SegmentParseV2 {
// ...
public static class Producer implements DataStreamReader.CallBack<UpstreamSegment> {
// ...
public void send(UpstreamSegment segment, SegmentSource source) {
SegmentParseV2 segmentParse = new SegmentParseV2(moduleManager, listenerManager, config);
segmentParse.setStandardizationWorker(standardizationWorker);
segmentParse.parse(new BufferData<>(segment), source); // 这里不仅仅简单做了parse,而是在里边顺着一路将数据入库了,后面会讲到
}
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
package org.apache.skywalking.oap.server.receiver.trace.provider.parser;
// ...
/**
* SegmentParseV2 replaced the SegmentParse(V1 is before 6.0.0) to drive the segment analysis. It includes the following
* steps
*
* 1. Register data, name to ID register
*
* 2. If register unfinished, cache in the local buffer file. And back to (1).
*
* 3. If register finished, traverse the span and analysis by the given {@link SpanListener}s.
*
* 4. Notify the build event to all {@link SpanListener}s in order to forward all built sources into dispatchers.
*
* @since 6.0.0 In the 6.x, the V1 and V2 analysis both exist.
* @since 7.0.0 SegmentParse(V1) has been removed permanently.
*/
@Slf4j
public class SegmentParseV2 {
// ...
public boolean parse(BufferData<UpstreamSegment> bufferData, SegmentSource source) {
createSpanListeners();
try {
UpstreamSegment upstreamSegment = bufferData.getMessageType();
List<UniqueId> traceIds = upstreamSegment.getGlobalTraceIdsList();
if (bufferData.getV2Segment() == null) {
bufferData.setV2Segment(parseBinarySegment(upstreamSegment));
}
SegmentObject segmentObject = bufferData.getV2Segment();
// Recheck in case that the segment comes from file buffer
final int serviceInstanceId = segmentObject.getServiceInstanceId();
if (serviceInstanceInventoryCache.get(serviceInstanceId) == null) {
log.warn(
"Cannot recognize service instance id [{}] from cache, segment will be ignored", serviceInstanceId);
return true; // to mark it "completed" thus won't be retried
}
SegmentDecorator segmentDecorator = new SegmentDecorator(segmentObject);
if (!preBuild(traceIds, segmentDecorator)) {
if (log.isDebugEnabled()) {
log.debug(
"This segment id exchange not success, write to buffer file, id: {}",
segmentCoreInfo.getSegmentId()
);
}
if (source.equals(SegmentSource.Agent)) {
writeToBufferFile(segmentCoreInfo.getSegmentId(), upstreamSegment); // 这里也需要关注一下,如果preBuild返回false,这里会将数据写入本地文件buffer暂存,后续还会消费一次
} else {
// from SegmentSource.Buffer
TRACE_BUFFER_FILE_RETRY.inc();
}
return false;
} else {
if (log.isDebugEnabled()) {
log.debug("This segment id exchange success, id: {}", segmentCoreInfo.getSegmentId());
}
notifyListenerToBuild(); // preBuild返回true后继续流转
return true;
}
} catch (Throwable e) {
TRACE_PARSE_ERROR.inc();
log.error(e.getMessage(), e);
return true;
}
}
// ...
private void notifyListenerToBuild() {
spanListeners.forEach(SpanListener::build); // 继续流转
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
package org.apache.skywalking.oap.server.receiver.trace.provider.parser.listener.segment;
// ...
/**
* SegmentSpanListener forwards the segment raw data to the persistence layer with the query required conditions.
*/
@Slf4j
public class SegmentSpanListener implements FirstSpanListener, EntrySpanListener, GlobalTraceIdsListener {
// ...
@Override
public void build() {
if (log.isDebugEnabled()) {
log.debug("segment listener build, segment id: {}", segment.getSegmentId());
}
if (sampleStatus.equals(SAMPLE_STATUS.IGNORE)) {
return;
}
if (entryEndpointId == Const.NONE) {
if (firstEndpointId != Const.NONE) {
/*
* Since 6.6.0, only entry span is treated as an endpoint. Other span's endpoint id == 0.
*/
segment.setEndpointId(firstEndpointId);
segment.setEndpointName(serviceNameCacheService.get(firstEndpointId).getName());
} else {
/*
* Only fill first operation name for the trace list query, as no endpoint id.
*/
segment.setEndpointName(firstEndpointName);
}
} else {
segment.setEndpointId(entryEndpointId);
segment.setEndpointName(serviceNameCacheService.get(entryEndpointId).getName());
}
sourceReceiver.receive(segment); // receive>forward>dispatch>in 四连
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
package org.apache.skywalking.oap.server.core.source;
// ...
public class SourceReceiverImpl implements SourceReceiver {
// ...
@Override
public void receive(Source source) {
dispatcherManager.forward(source); // receive>forward>dispatch>in 四连
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
package org.apache.skywalking.oap.server.core.analysis;
// ...
public class DispatcherManager implements DispatcherDetectorListener {
// ...
public void forward(Source source) {
if (source == null) {
return;
}
List<SourceDispatcher> dispatchers = dispatcherMap.get(source.scope());
/**
* Dispatcher is only generated by oal script analysis result.
* So these will/could be possible, the given source doesn't have the dispatcher,
* when the receiver is open, and oal script doesn't ask for analysis.
*/
if (dispatchers != null) {
for (SourceDispatcher dispatcher : dispatchers) {
dispatcher.dispatch(source); // receive>forward>dispatch>in 四连
}
}
}
// ....
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package org.apache.skywalking.oap.server.core.analysis.manual.segment;
// ...
public class SegmentDispatcher implements SourceDispatcher<Segment> {
@Override
public void dispatch(Segment source) {
SegmentRecord segment = new SegmentRecord();
segment.setSegmentId(source.getSegmentId());
segment.setTraceId(source.getTraceId());
segment.setServiceId(source.getServiceId());
segment.setServiceInstanceId(source.getServiceInstanceId());
segment.setEndpointName(source.getEndpointName());
segment.setEndpointId(source.getEndpointId());
segment.setStartTime(source.getStartTime());
segment.setEndTime(source.getEndTime());
segment.setLatency(source.getLatency());
segment.setIsError(source.getIsError());
segment.setDataBinary(source.getDataBinary());
segment.setTimeBucket(source.getTimeBucket());
segment.setVersion(source.getVersion());
RecordStreamProcessor.getInstance().in(segment); // receive>forward>dispatch>in 四连
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package org.apache.skywalking.oap.server.core.analysis.worker;
// ...
public class RecordStreamProcessor implements StreamProcessor<Record> {
// ...
public void in(Record record) {
RecordPersistentWorker worker = workers.get(record.getClass());
if (worker != null) {
worker.in(record); // receive>forward>dispatch>in 四连
}
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
以上就是枯燥的receive>forward>dispatch>in四连,下面开始就是Elasticsearch提供的BulkProcessor支持的批量写入了
package org.apache.skywalking.oap.server.core.analysis.worker;
// ...
public class RecordPersistentWorker extends AbstractWorker<Record> {
// ...
@Override
public void in(Record record) {
try {
InsertRequest insertRequest = recordDAO.prepareBatchInsert(model, record); // 将数据放进InsertRequest
batchDAO.asynchronous(insertRequest); // 准备批量写入
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package org.apache.skywalking.oap.server.storage.plugin.elasticsearch.base;
// ...
public class BatchProcessEsDAO extends EsDAO implements IBatchDAO {
//...
@Override
public void asynchronous(InsertRequest insertRequest) {
if (bulkProcessor == null) {
this.bulkProcessor = getClient().createBulkProcessor(bulkActions, flushInterval, concurrentRequests);
}
this.bulkProcessor.add((IndexRequest) insertRequest); // 将IndexRequest暂存起来
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这里就不将BulkProcessor展开讲了,它是Elasticsearch提供的Java client中的一部分,可以支持高效的并发批量写数据进Storage
那么至此,我们已经掌握到的具体信息如下:
- probe端:启用了一个线程数为1,自选等待时间为20ms的consumer来消费buffer
- probe端:每次消费掉buffer中所有内容,取到consumeList
- probe端:在for循环中,将consumeList里的segment一个个用gRPC协议发往backend端
- backend端:拿到segment后开始处理过一些业务逻辑后(处理出错的会写磁盘buffer文件,后续处理)
- backend端:开始receive>forward>dispatch>in四连,最后用BulkProcessor批量写入Elasticsearch
现在看起来只有4处明显可以靠参数调优的地方了
- probe端:consumer数量(默认:1)
- backend端:BulkProcessor的bulkActions(默认:1000)
- backend端:BulkProcessor的flushInterval(默认:10)
- backend端:BulkProcessor的concurrentRequests(默认:2)
那么本着先从probe端开始调优的原则,尽量减少变量
我们先把probe端consumer数量从1调成8好了,因为我司机器普遍是8核
probe端日志:
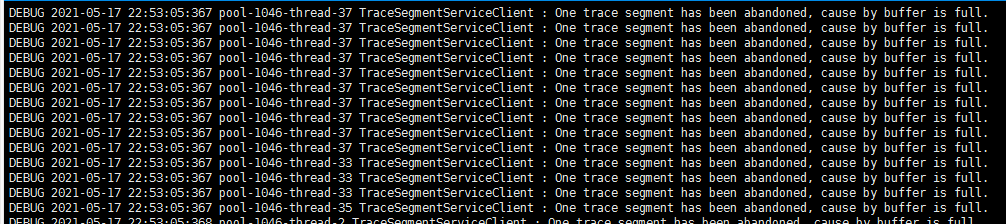
backend端日志:

python统计日志:

虽然看probe端和backend端日志并没有太大区别,但是成功入库的segment数量从原来的2w5涨到了5w
可以看出来优化生效了,看来确实是之前调大了probe端buffer以及消费线程数生效,我们现在尝试对backend端参数调优
bulkActions设为10000,flushInterval保持不变,在并发量大的时候这个参数其实并不影响什么,concurrentRequests设为20
probe端日志:

backend端日志:

python统计日志:
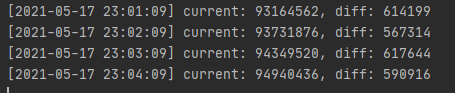
可以发现probe端鲜有见到被丢弃的数据了,且backend端日志也很正常
最重要的是,python统计日志里能看到往Elasticsearch里基本上是达到了600k的写入!
可以说现阶段单实例的SkyWalking已经抗住了C10K的目标
# 总结
我们已经通过修改一些参数,初步达到了我们调优的目的,不过后续我们还要持续关注一下probe端资源占用情况,不能够过于影响宿主应用,今天搞太晚了,明天继续~