# 5. 多变量线性回归
# 多功能
在之前的例子中,我们使用房屋的面积来预测价格
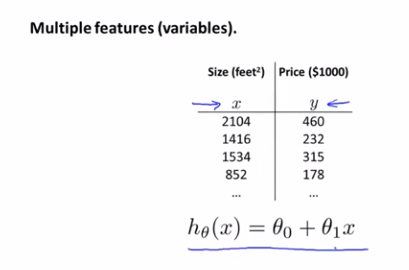
但是我们现在有更多数据,比如:面积/卧室数/楼层数/年龄
现有如下定义:
n表示特征的数量x^(i)表示训练集里边第i个样本,它是一个n维向量x^(i)_j表示训练集里第i个样本中的第j个特征量
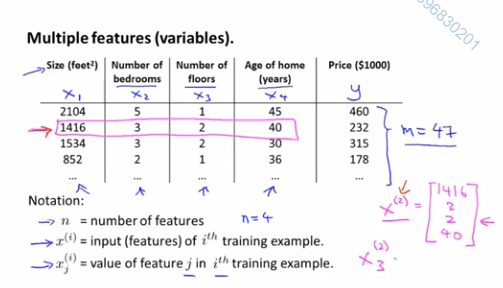
之前的简单假设函数只有1个特征值,也就是房屋面积
之后的会有4个或更多特征值

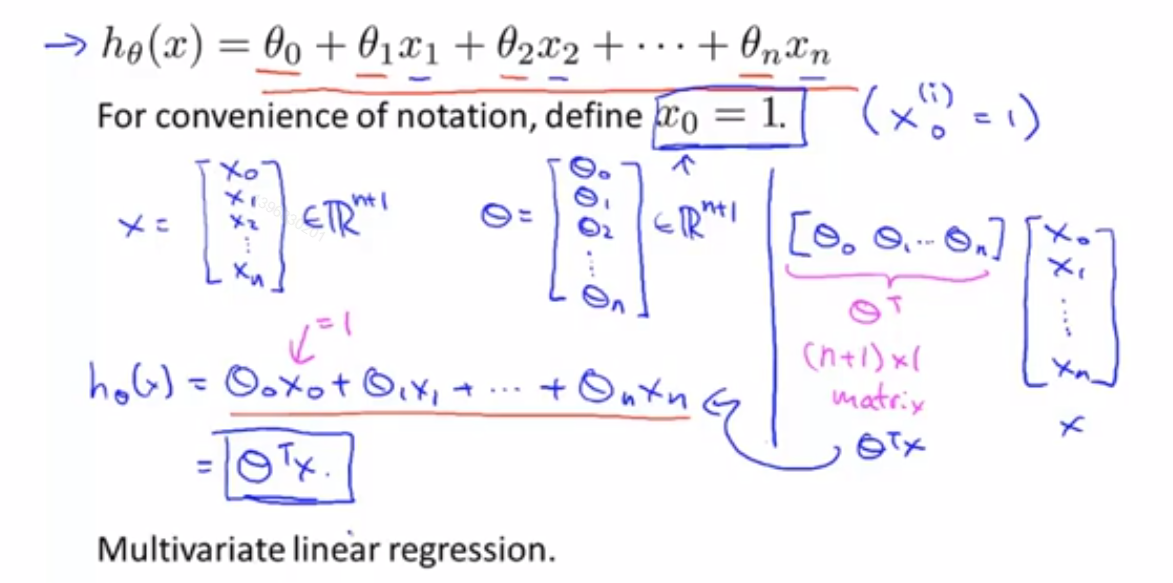
我们现在可以把式子简化表达成2个矩阵的乘积形式
h_θ(x)=θ_0+θ_1*x_1+θ_2*x_2+...+θ_n*x_n
=θ^T*x
2
# 多元梯度下降法
当我们把参数用矩阵/向量的形式表达后,我们可以把代价函数简化如下

回顾之前第2章讲的梯度下降算法的求偏导的结论可得如下式子

# 多元梯度下降法演练1:特征缩放
当我们在做梯度下降的时候,有多个特征,我们应该尽量确保这些特征都处于一个相近的范围内,这样梯度下降法能更快地收敛
假设我们有2个特征,x_1为房屋面积(0-2000平方英尺),x_2为卧室数量(1-5个),当我们画出代价函数J(θ)等值线图像,会发现图像是个非常扁长的椭圆,因为2个特征的取值范围相差过大,当我们运行梯度下降算法的时候,可能会来回波动并花很长一段时间才能最终收敛到全局最小值
那么这种情况下,我们可以采用特征缩放的方式来优化
我们令x_1为原值的1/2000,x_2为原值的1/5,这样的好处是可以使2个特征值都处于[0,1]区间内,等值线图像更近似一个正圆,代价函数可以更快地找到全局最小值
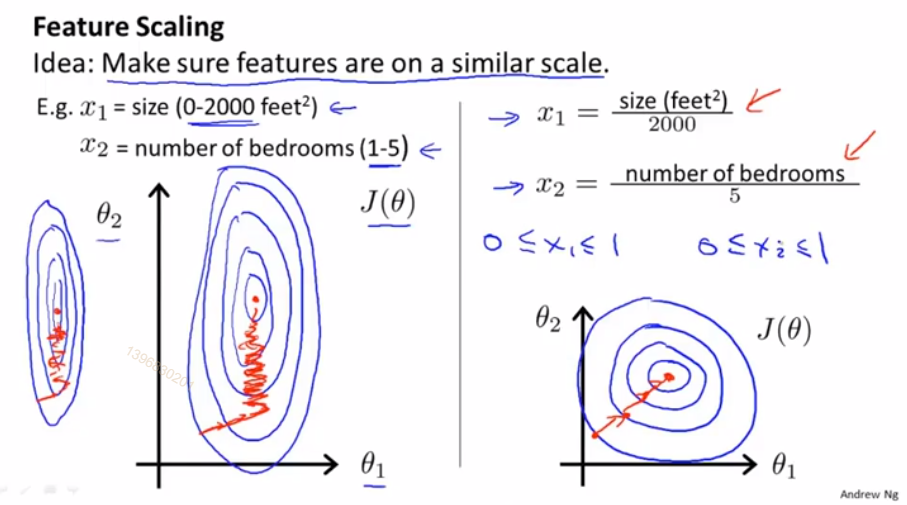
尽量确保特征值缩放在[-1,1]区间内,只要差别不是特别大都可以接受

我们也可以对特征值做平均归一化,令x_1=(x_1-μ_1)/s_1,其中μ_1为样本中平均值,s_1为变量的标准差,其实也可以用样本中最大值与最小值的差值作为s_1

# 多元梯度下降法演练2:学习率
下面讲一些小技巧来确定梯度下降是正常工作的
以及如何选择学习率α

梯度下降算法做的事情就是找到一个θ值,并且希望它能够最小化代价函数J(θ)
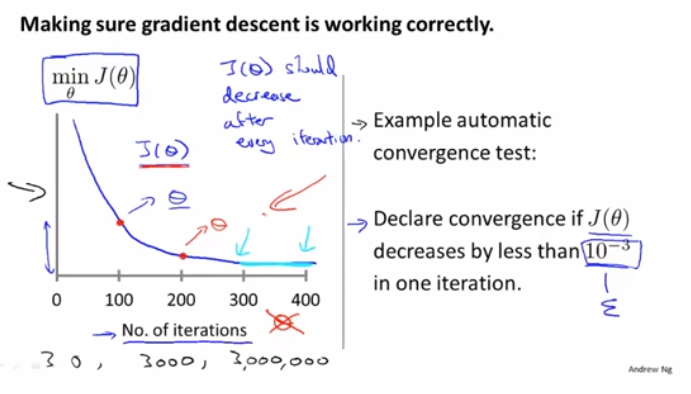
所以我们可以在梯度下降算法运行时,绘出代价函数J(θ)的值和梯度下降算法迭代次数的图像,如果算法正常工作的话,每一步迭代之后J(θ)都应该下降,我们可以从图像看出在300步之后,曲线看起来就非常平坦了,算法差不多已经收敛了,因为代价函数没法再继续下降更多了
对于不同问题,梯度下降算法所需的迭代次数可能相差会很大,某些可能只需要30步就可以收敛,其它需要可能300甚至300w步
另外,也可以进行一些自动的收敛测试,如果代价函数J(θ)一步迭代后的下降小于一个很小的值ε,这个测试就判断函数已经收敛,ε可以是1e-3,但是通常来说,选取一个合适的ε是非常困难的,所以还是倾向于查看图像来判断函数是否收敛
如果我们发现代价函数J(θ)随着迭代次数增大或者波动,说明我们需要选取更小的学习率α,但如果选取过小的α,也会导致梯度下降算法过慢收敛
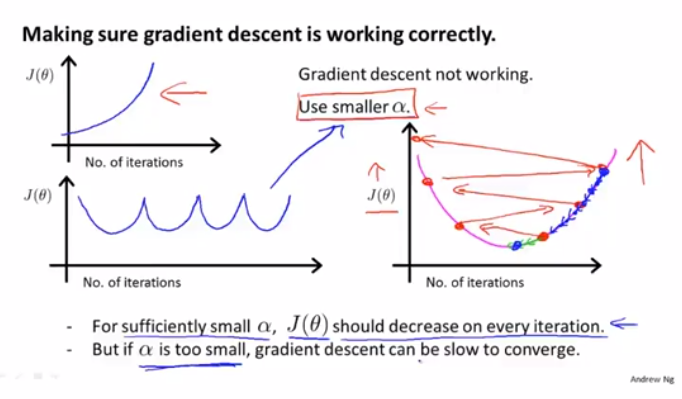
一般会按增大3倍来选取α

# 特征和多项式回归
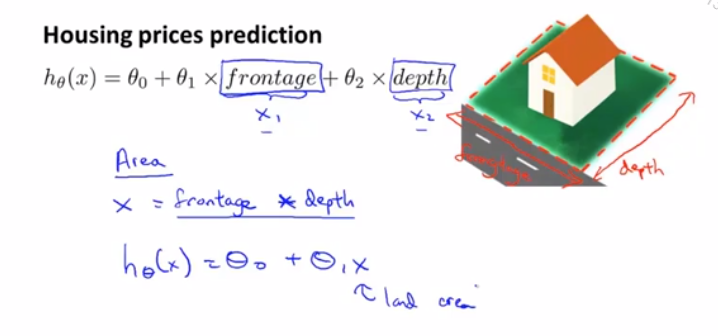
假设我们需要预测房屋价格,有2个特征值,frontage是房屋临街宽度,depth是房屋垂直宽度,但我们并不一定要用给出的数据列作为特征,可以自己创造新的特征,比如房屋面积area=frontage*depth,有时这样可以得到一个更好的模型
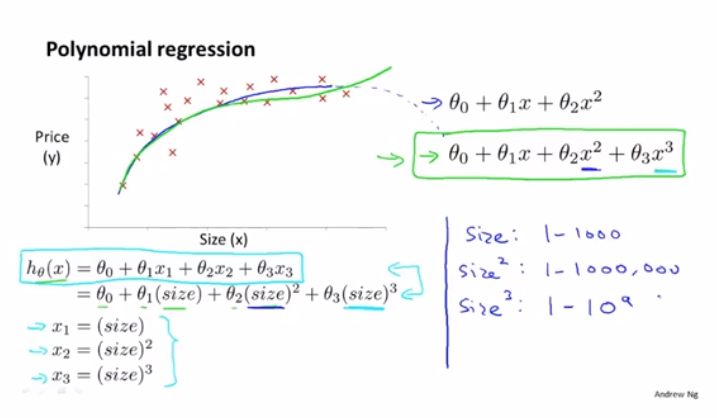
多项式回归(polynomial regression)
当我们要对一些点做拟合的时候,有时3次函数会比2次函数更合适,因为2次函数图像在本例中最终会下降,但显然房屋价格并不会这样
而使用3次函数做拟合的话,特征缩放就非常重要了,如果房屋面积x范围在1-10^3平方英尺,那么x^2范围就在1-10^6平方英尺,而x^3范围在1-10^9平方英尺了
我们甚至可以选用开根号函数来拟合

之后将探讨一些算法,它们能够自动选择要使用什么特征
# 正规方程(区别于迭代方法的直接解法)
目前为止,我们一直在使用的线性回归算法是梯度下降算法,为了最小化代价函数J(θ),我们需要很多步迭代,才能收敛到全局最小值
而正规方程(normal equation)提供了一种求θ的解析解法,不需要迭代,可以直接一次性求解θ的最优值
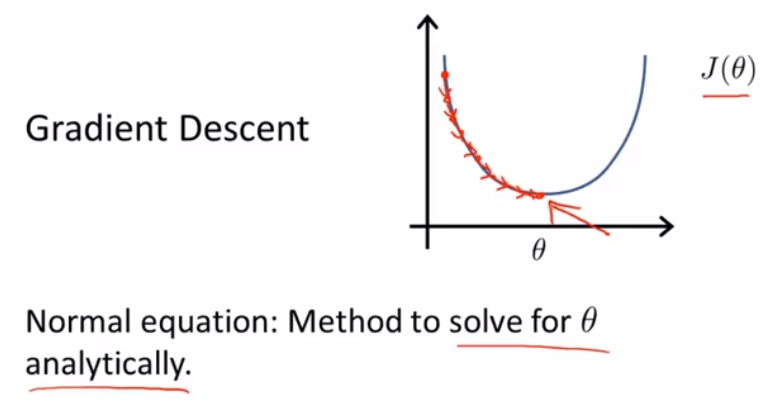
我们先假设有个非常简单的代价函数J(θ),它是个关于θ的二次函数,我们可以用微积分对J(θ)求导,并让它的导函数值为0,那么此时满足条件的参数横坐标值即为J(θ)最小值横坐标取值
以上是θ为实数的一个简单情况,而θ在其它情况下是一个n+1维的参数向量,那我们该如何最小化代价函数J(θ)呢,微积分告诉我们可以逐个对参数θ_j求j的偏导数,然后把它们全部置零,这样求出所有的θ_0,θ_1一直到θ_n,就能够得到最小化代价函数J(θ)的各个θ值了
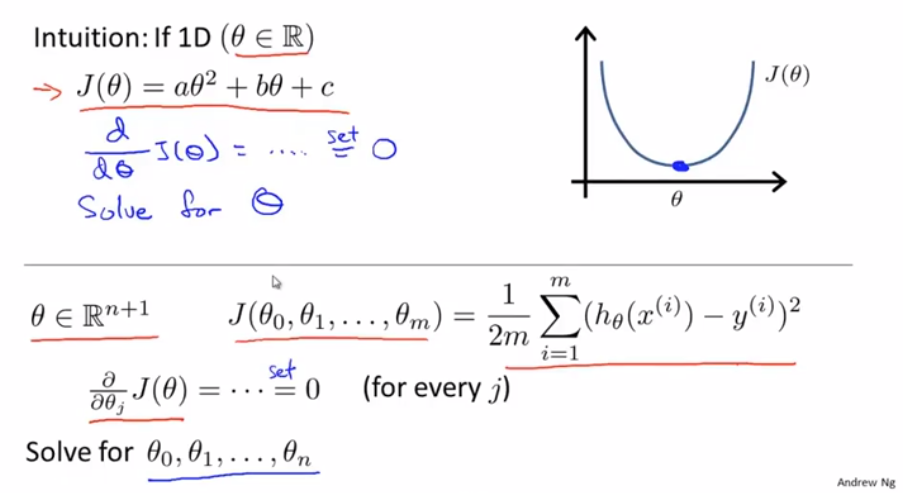
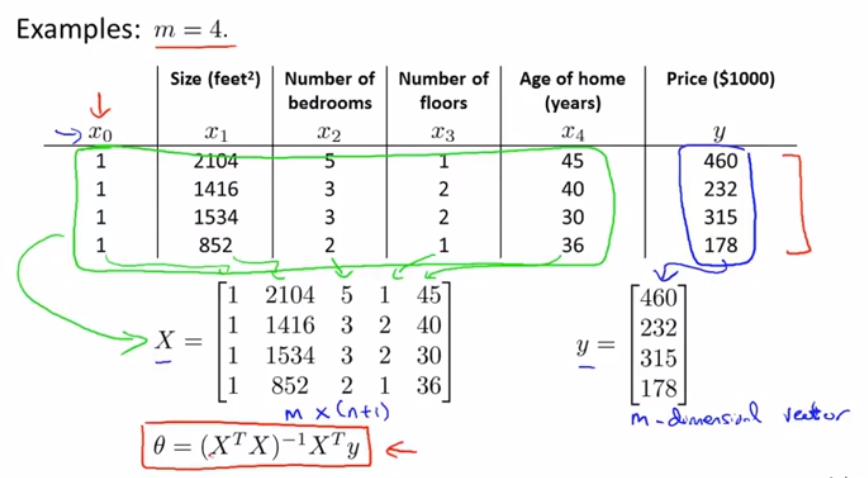
我们来看一个样本数量为4的训练数据集,我们要做的是先在数据集中,加上一列,对应额外特征变量的x_0,它的取值永远是1,接下来,构建一个矩阵X,它包含了训练样本的所有特征变量,再构建一个向量y,它包含了所有预测值,所以矩阵X是一个m*(n+1)的矩阵,而y是一个m维向量,其中m为样本数量,n为特征值的数量
那么通过θ=(X^T*X)^(-1)*X^T*y,就能得到使代价函数最小化的θ
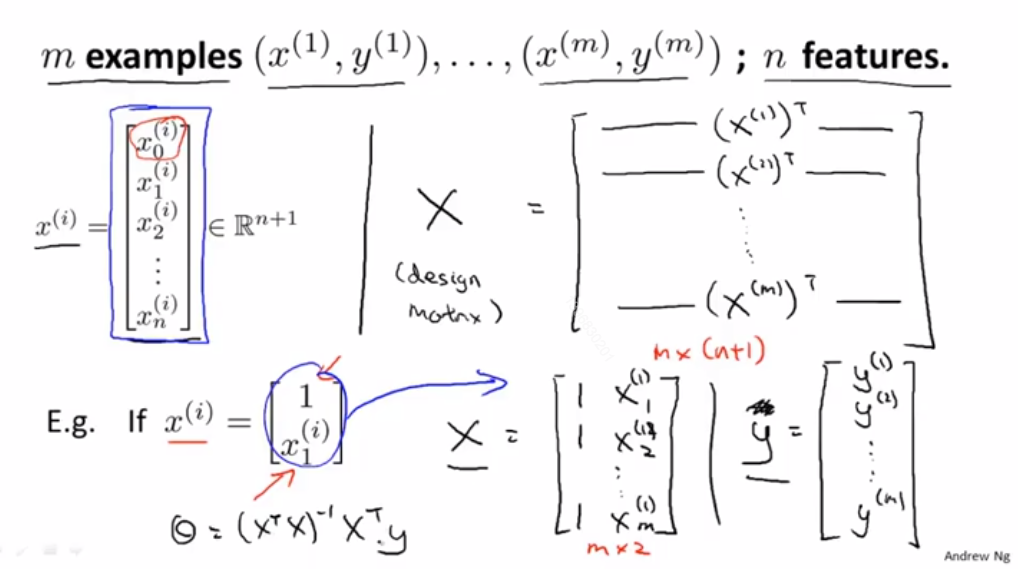
下面是构建设计矩阵(design matrix)的过程,有m个样本,其中x^(1)就是上图中[1,2104,5,1,45]这个n+1维向量,那么(x^(1))^T就是[1,2104,5,1,45]这个1*(n+1)的矩阵,当i从1自增到m,我们就可以得到m*(n+1)维的设计矩阵X了
(吴恩达老师说并不打算证明这个式子是如何计算出最小θ...但是数学上是可以证明的)
正规方程法可以不需要对特征值做特征缩放,即可一步出解
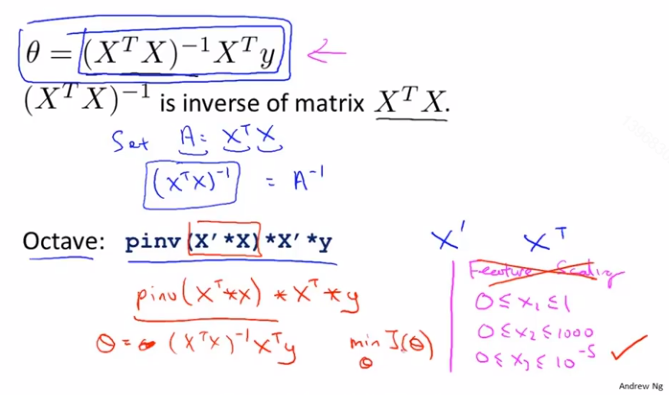
那么我们何时应该选用梯度下降法,何时应该选用正规方程法呢?
假设我们有m个训练样本,n个特征变量
梯度下降法:
- 需要选取合适的学习速率
α - 需要很多步迭代(计算可能会很慢)
- 当特征变量
n非常多的情况下(即使上百万),也能运行得很好
正规方程法:
- 不需要选取学习速率
α - 不需要迭代
- 计算矩阵的代价大概在
O(n^3)的时间,如果n特别大,效率会慢很多
当n在10^4量级以下,正规方程法会比较合适,超过10^4量级,梯度下降法更快

# 正规方程在矩阵在矩阵不可逆情况下的解决方法
Octave中有2个函数可以求逆矩阵,pinv()和inv(),使用pinv()总能求解出θ,即使X^T*X不可逆

X^T*X不可逆,通常有2种常见原因
- 多余/线性相关的特征(例如:
x_1是平方英尺房屋面积,x_2是平方米房屋面积) - 过多的特征(例如:
m<=n,样本容量m为10,特征数量n为100)